














Esta semana, en el MOOC Analíticas de aprendizaje y ciencias de datos en educación, la hemos dedicado a descubrir las fuentes de datos que tenemos a nuestra disposición, y que de una manera muy interesante describen a nuestros centros educativos, sus aulas, las personas que allí aprenden y enseñan y la actividad académica en general.
El título de este post no ha sido idea nuestra, fue Mira Murati, exdirectora de tecnología de OpenAI (los creadores del célebre ChatGPT), quien pronunció estas palabras, señalando que, si las aplicaciones de inteligencia artificial aprenden de los datos, los datos, de algún modo, forman parte de su código fuente; y es imprescindible aportar datos de calidad, que representen la totalidad del problema, que estén libres de sesgos y que aseguren un aprendizaje justo a la IA.
Durante estas dos semanas que ya hemos pasado juntos hemos descubierto la potente intersección entre informática, estadística y pedagogía, el ikigai en el que encontramos a las ciencias de datos educativos, las analíticas de aprendizaje o la minería de datos en educación. Disciplinas que, apoyándose en las tecnologías más vanguardistas, ponen a los estudiantes en el centro para brindarles mejores experiencias académicas y más oportunidades para superar sus dificultades.
Hemos aprendido a identificar las diferentes fuentes de datos a nuestra disposición, cómo seleccionarlas en cuanto a sus posibilidades, cómo evitar sesgos en nuestros datos, y hemos dado unos primeros pasos hacia el diseño de un dataset que nos podría permitir obtener información valiosa para mejorar la enseñanza, los aprendizajes y los entornos en los que estos se producen: ya sean físicos o virtuales.
Como resultado de esta práctica, que os hemos propuesto, hay trabajos que merecen ser compartidos, ya que pueden ser una fuente de inspiración para muchos otros participantes.
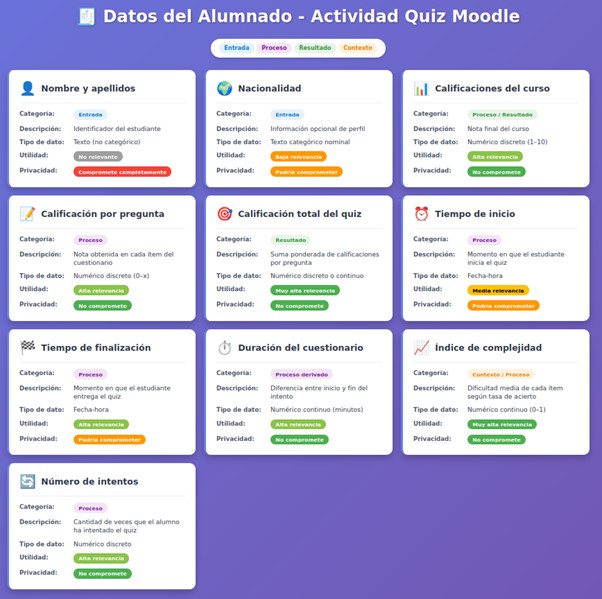
Margarita Inaraja ha compartido una creación, hecha con Claude Artifacts, para ilustrar los datos a los que puede tener acceso, y su conveniente categorización, a partir de un cuestionario de Moodle como fuente.
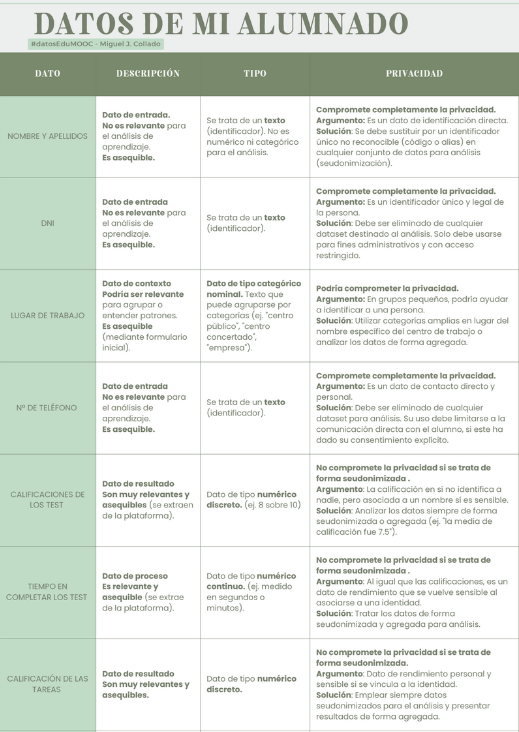
Por su parte, Miguel J. Collado, ha optado por una tabla clara y vistosa, en la que describe las diferentes fuentes de datos que componen la huella digital de su alumnado. Miguel describe con detalle el preprocesamiento necesario en estos datos para la salvaguarda de la privacidad y los datos de carácter personal.
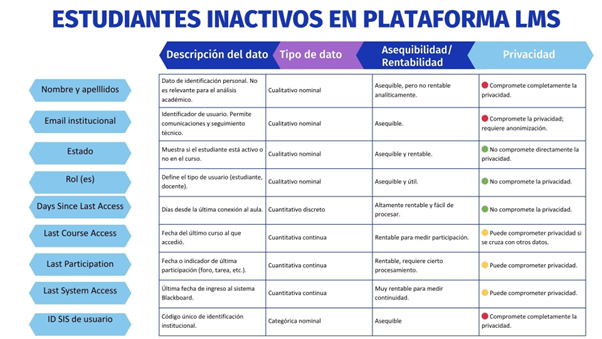
Para finalizar, compartimos también la producción de Fernanda Ulloa, que nos desglosa y categoriza los datos que se pueden obtener de un LMS, como Moodle, en cuanto a la actividad de los usuarios en la plataforma.
Esperamos que esta segunda semana os haya sido de provecho. Seguimos….